I’ve had this Arty A7-35 around for a while, and discovered that ARM has released some Cortex-M3 core example implementations for this board. They’ve been out for a couple years, but they’re new to me. I documented the whole flow in a tutorial on my github as I worked through it, and then decided to try my hand at creating a video walk-through.
This video walks you through the basics of getting the Xilinx Vivado software running, programming the board with a pre-made image, unpacking and synthesizing the ARM Cortex-M3 model, compiling the example Cortex-M3 software, and then merging the memory image into your bitstream file.
For the next installment I want to walk through how to add an AXI peripheral using the IP Integrator/Block Design tool, add some custom RTL to the peripheral, and add a few lines of software to interface with it.
I learned a lot through the process of recording and editing this video that I can use to make the next one even better!
I’ve had this Arty A7-35 around for a while, and recently discovered that ARM has released some Cortex-M3 core example implementations for this board.
This tutorial walks you through the basics of getting the Xilinx Vivado software running, programming the board with a default image, unpacking and setting up the ARM Cortex-M3 model, compiling the example Cortex-M3 software, and merging that into your bitstream file.
For the next installment I want to walk through how to add an AXI peripheral using the IP Integrator/Block Design tool, add some custom RTL to the peripheral, and add a few lines of software to interface with it.
I learned a lot through the process of recording and editing this video that I can use to make the next one even better!
In my original RedDelta analysis (which I did for the final project of my Malware Analysis class), I took a new malware sample from The Zoo that I really had no information about – just five unnamed files, and did an analysis of two files that I found within – the malware loading program and a related DLL. There was no information online regarding where the malware had come from – the sample had just been uploaded five days earlier, and there weren’t any other analyses of it online. That’s why I chose it though – I wanted to go into it blind for the challenge.
There was a file that I didn’t get to though, because it was a 64-bit executable and the tools I was using for class weren’t set up for that. Recently I started putting together a new VM with updated tools to take a look at that file, and when I searched for it online again I found that there is *much*moreinformation available about it now in the form of highly detailed reports.
It turns out that RedDelta is a hacking group widely believed to be sponsored by the Chinese government, and possibly related to another group called Mustang Panda. The malware was found on machines in the Vatican, which would explain why the names of both of the lure documents relate to the Catholic church. It has also been seen in attacks on the Catholic Diocese of Hong Kong as well as police and government organizations in Indonesia and India.
There are high-level talks going on between the Vatican and China right now, that have been planned for a couple years – there was an agreement in 2018 and it was expected that it would need to be renewed. The talks relate to how much control the Vatican has over the Catholic organizations in China vs. how much control the Communist Party has – for instance, who gets to appoint bishops. It appears that RedDelta was working to infiltrate computer systems in the Vatican in order to gather intelligence about Vatican opinions and strategy going into these talks, presumably so that China could have the upper hand in negotiations.
So, it has been really cool and interesting to basically grab some unnamed files from an archive and end up working on malware that is actively being used for political gain in world events.
As I mentioned, I’ve been working on spinning up a new Windows 10 VM and researching the current tools for 64-bit malware analysis. My goal is to do a full analysis of the 64-bit executable I found. Originally I had thought that was a 64-bit version of the loader, but now I believe it’s actually the payload – the original hk.dat file that was downloaded and installed on the victim’s machine when the user opened what they thought was a Word document.
From my initial forays it is *much*, much more complicated than the loaders, containing Visual Studio libraries and encryption routines – I presume for command-and-control communications. The report above says that it is a fairly well-known malware variant called PlugX.
My goal is still to do a Part 2 and detail my analysis of File #5 (presumably the PlugX payload). I’m currently debating how much I want to continue doing this blind, vs. researching what is known about PlugX and using that to help direct so I don’t waste time analyzing Microsoft libraries. There are *hundreds* of unnamed functions to work through. I also picked up The Ghidra Book and am learning that tool as I go.
Classes just started up again so I’m sure that will keep me busy, but I’m excited to continue working on this and will post Part #2 when I can.
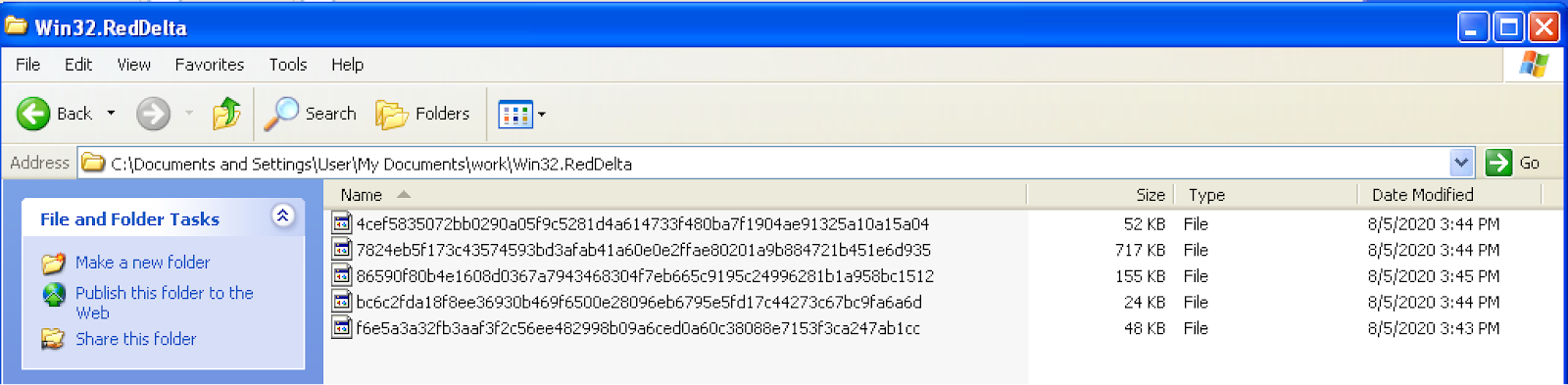
For my Malware Analysis class, my final project was to choose a malware sample from the wild and do an analysis of it. In our class we’ve been focusing on 32-bit x86 malware to make things simpler – that’s generally for Windows XP or Vista – around 10 years old or so. But while I was looking at the Zoo for 32-bit malware samples I ran across one that had been uploaded just the week before called Win32.RedDelta. I googled it and couldn’t find *any* information about it at all, and when I downloaded it the archive contained five files with apparently randomly generated names and no extensions. It seemed like a great challenge to see what I – who had never done this from scratch before – could figure out about it.
To summarize, I found an executable file made to look like a politically challenging Word document, and an accompanying DLL. If you clicked on the file it would create an actual Word document and open it so you may not realize you had just run a malicious program. Then it would call routines in the DLL to contact a website, download a malicious payload, decompress and unpack/decode it, and execute that code.
The rest of this is from my final project presentation:
The RedDelta malware sample had been uploaded to the Zoo on August 5th – just the week before.
I had been debating analyzing something like Stuxnet, but there was so much available online about it I didn’t want to duplicate other work. When I searched Google about RedDelta I didn’t found any information about it whatsoever. I downloaded and unzipped the archive and found five files with seemingly random names, no extensions or other identifiable information.
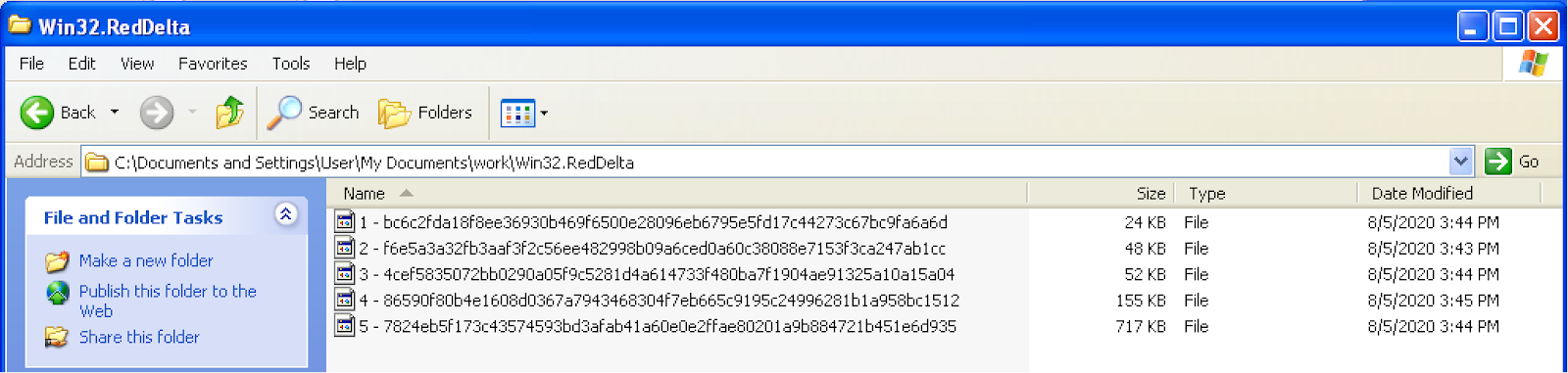
This seemed like an interesting challenge, so I decided to go for it. I re-numbered them smallest to largest
and just started working my way down the list.
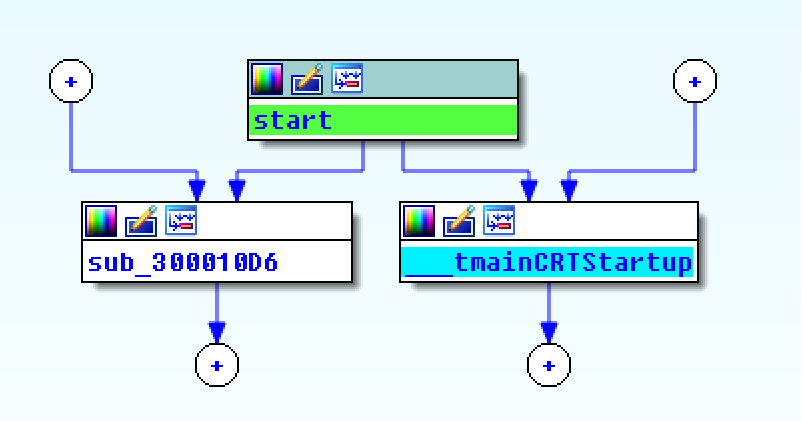
Going down the list – File #1:
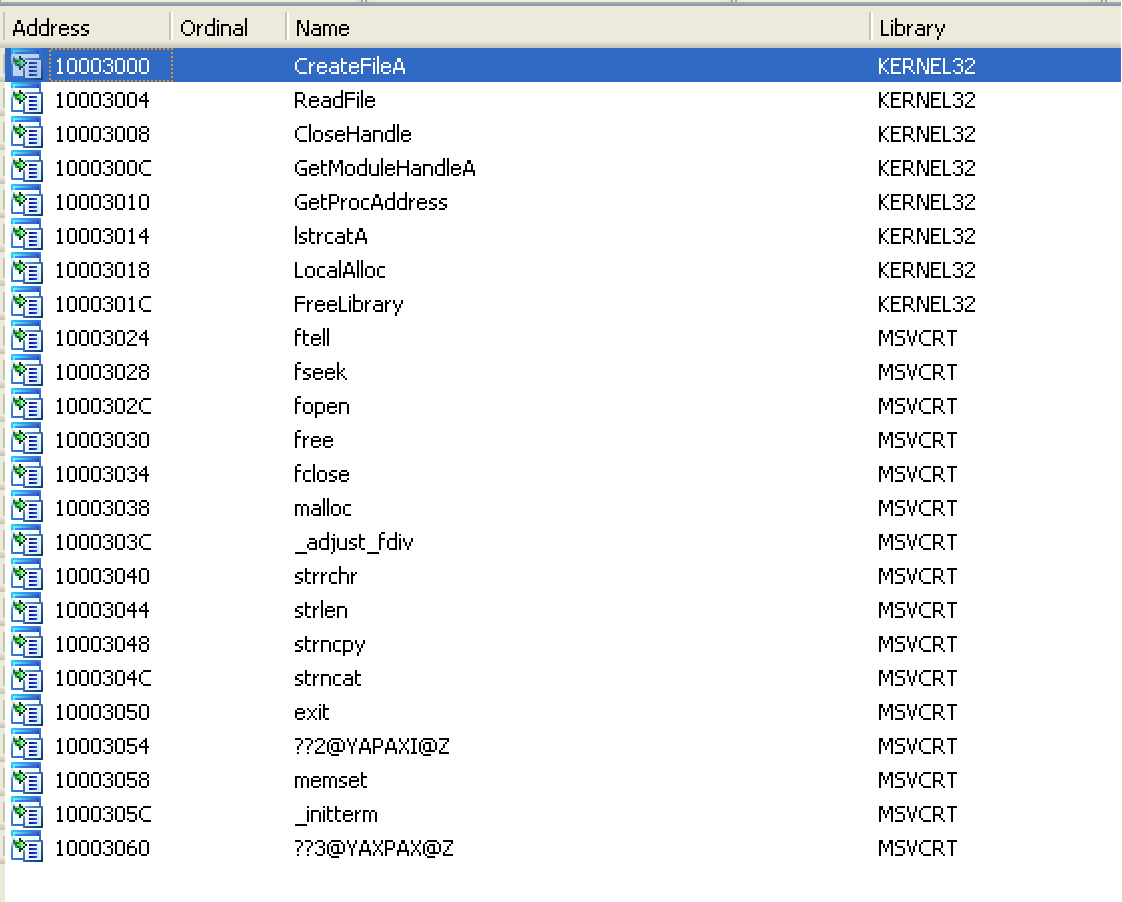
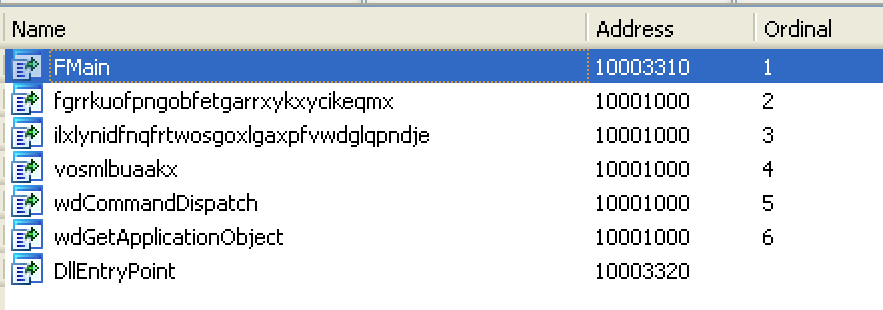
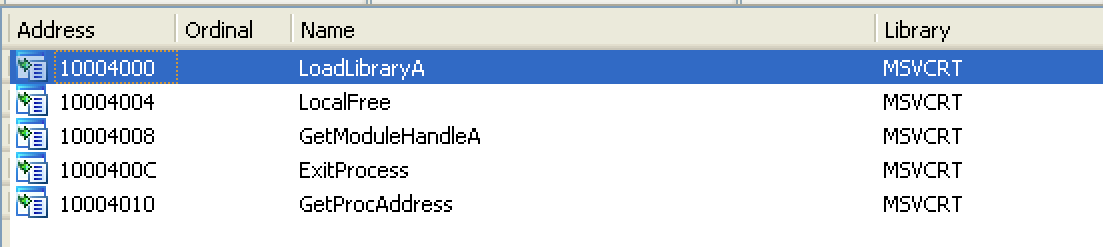
Using PEview and Ida Pro, I can see that File #1 is a DLL with process handling and file handling imports:
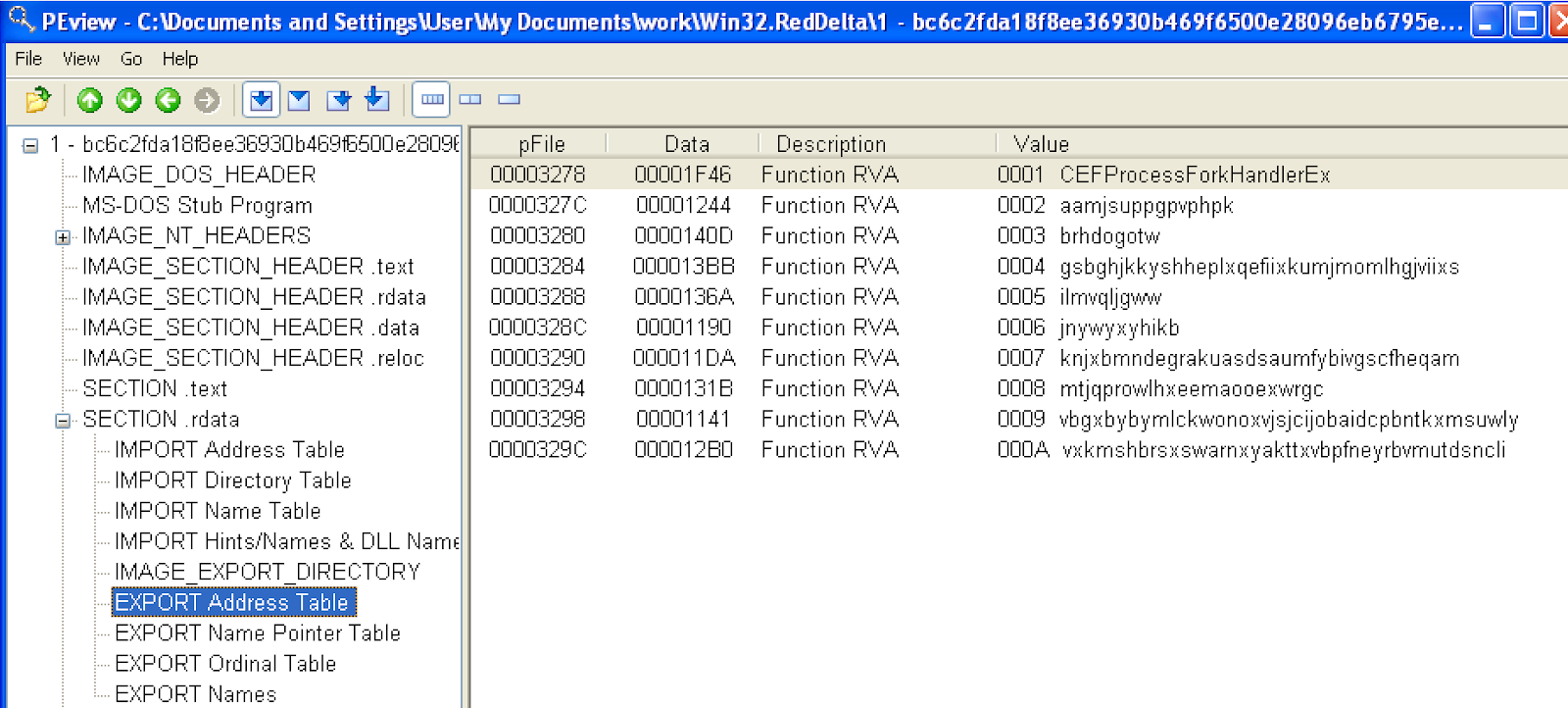
It also has exports, seemingly randomly-named:
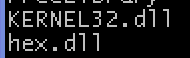
Using strings, you can see references to KERNEL32.dll, and hex.dll:
Going down the list – File #2:
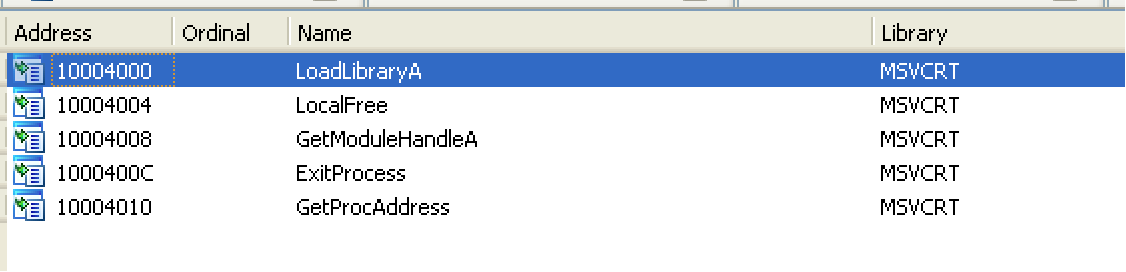
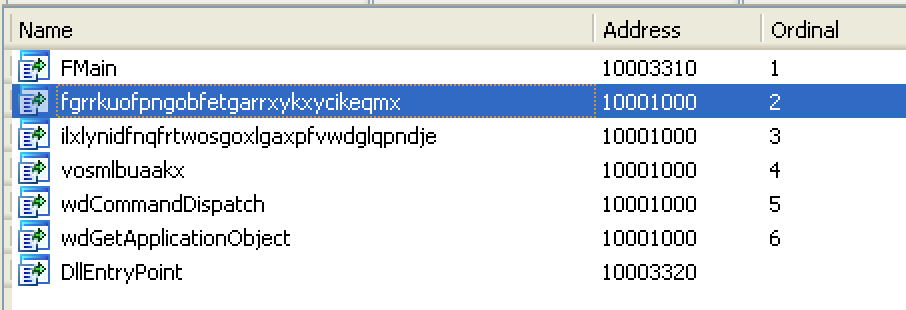
File #2 also appears to be a DLL – lots of Word-related strings, and a document name. It has process and module-loading imports, and again, seemingly randomly-named exports.
You can see a lot of strings that look related to Word documents, and in fact can see an intriguing document name:
Going down the list – File #3: File #3 is a DLL almost identical to file #2 – the same Word-related strings and the same number of imports/exports, although the random names are different and we see a different document name – apparently in Italian.
Going down the list – File #4:
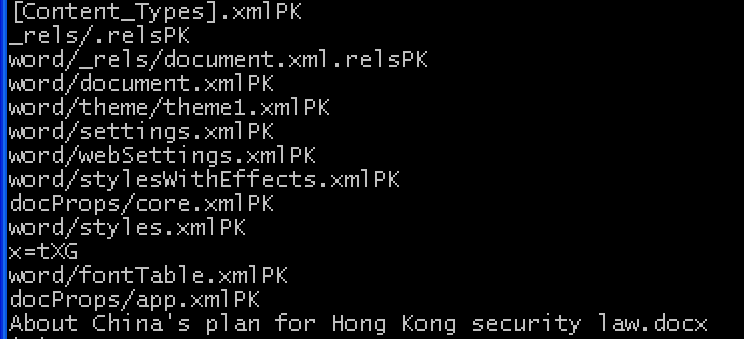
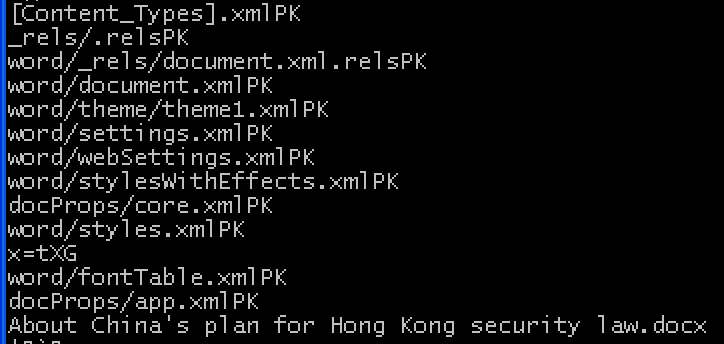
File #4 turns out to not be a Windows’ PE file at all – it looks like a zip archive based on the PK/ZF strings and now-familiar filenames:
We’ll come back to this…
Going down the list – File #5:
File #5 looks like a 64-bit executable. At the time I wasn’t equipped to examine this safely – we were using an XP virtual machine with a 32-bit version of Ida Pro. I’m currently setting up a 64-bit image with malware analysis tools, will get back to this one in Part 2.
You can see a libcurl reference and some network-related error messages though:
Back to File #4 – File 4-1:
Ida pro confirms that File #4 is an archive:
Ida pro will apparently analyze the contents in the archive, but I rename the file with a .zip extension and Windows is happy to unzip the two contained files:
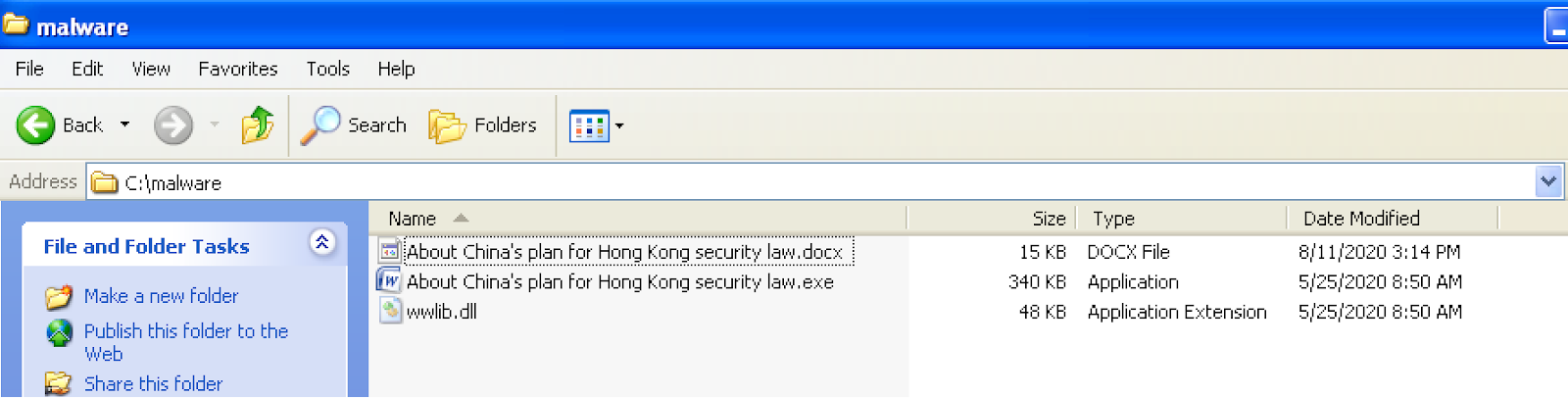
File 4-1, while taking pains to appear like a Word document, is actually an executable. It has a Word document icon, but an .exe extension.
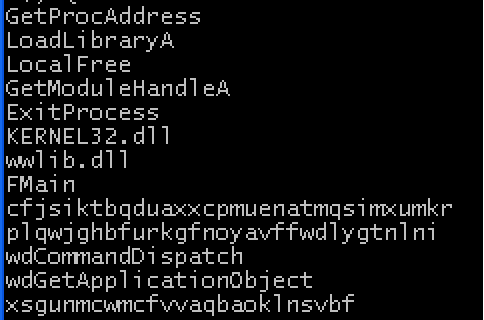
Strings shows a reference to wwlib.dll (File 4-2), KERNEL32.dll and process-managing routines, and randomly-named functions like we saw in the DLLs:
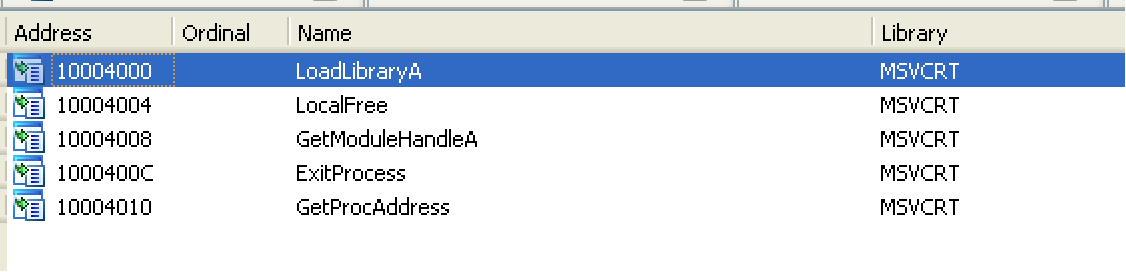
The imports list shows some process-handling and DLL loading routines – but the most interesting/suspicious ones are IsDebuggerPresent() – indicating it’s looking to see if it is being analyzed in a debugger so it can act differently – and VirtualProtect(), which can change the permissions of memory contents.
Back to File #4 – File 4-2:
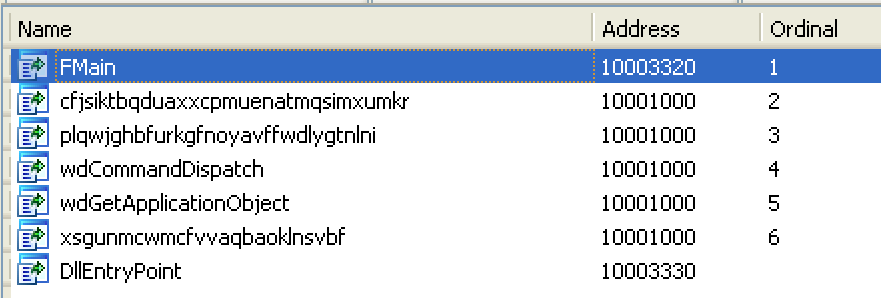
File 4-2 is called wwlib.dll, which sounds like it could be an innocuous Windows DLL, but isn’t.
These imports, exports and strings are starting to look familiar:
Decision Time:
Having looked at the original five files, it appears we have three similar versions of the same DLL, one different DLL, a 32-bit executable and a 64-bit executable.
I decided to just focus on the two extracted files as they had names and I’m reasonable sure they belong together – were likely extracted from the same host machine.
I’ll come back to the different DLL and the 64-bit executable in Part 2.
File 4-2 – wwlib.dll Static Analysis:
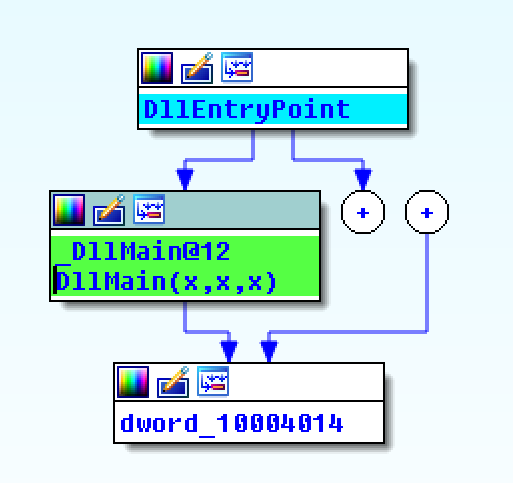
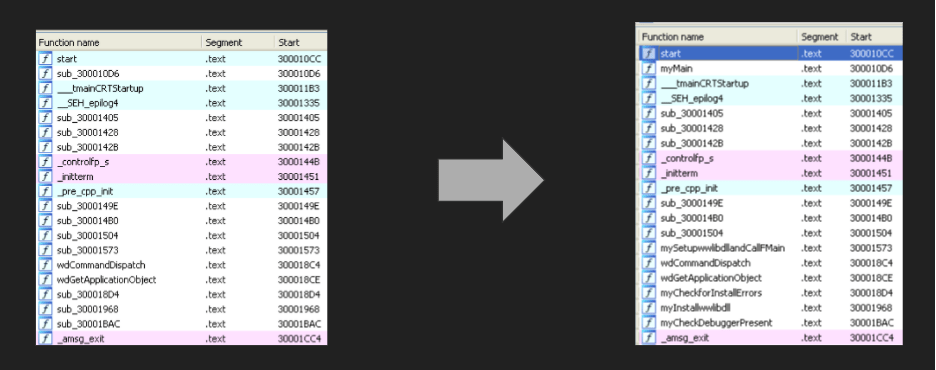
Starting with wwlib.dll, I loaded it into Ida Pro. It has no idea what the functions should be called, so calls them sub_<address>. Over the course of my time with it I examined and renamed all the functions with what I determined they were about:
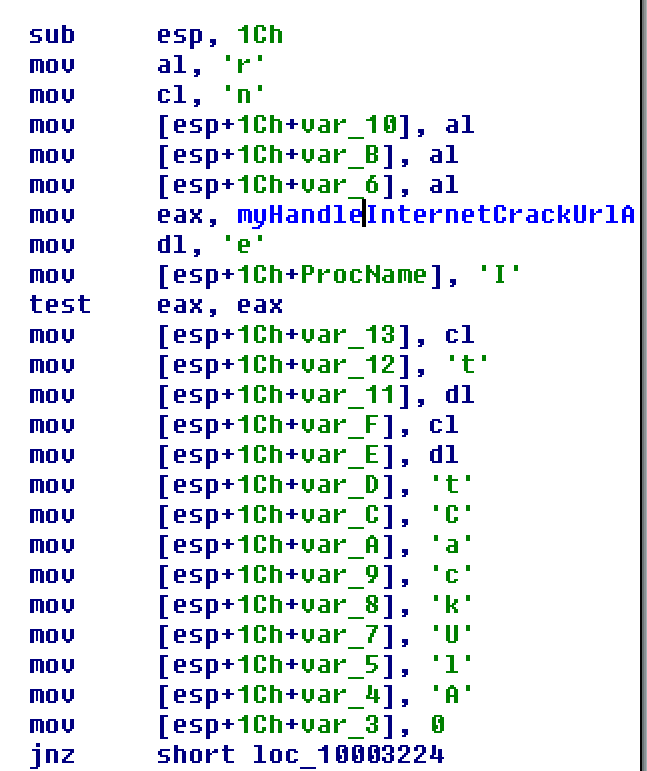
The first thing I noticed is that the malware uses this string-hiding method to hide the names of the external functions it calls – it builds the name from individual characters stored in memory so they’re not visible with a strings-type tool. It uses this method *everywhere*, for every external function call:
This code must be the result of a compiler or automated post-processing as it is inefficient and inconsistent. Some letters have a second level of indirection with being stored in a register, but it doesn’t really stop you from figuring out what they are. Also different instances of the same string hide different letters, so if you see the same similar name multiple times you can determine all the letters.
This one decoded to InternetCrackUrlA() in the wininet library.
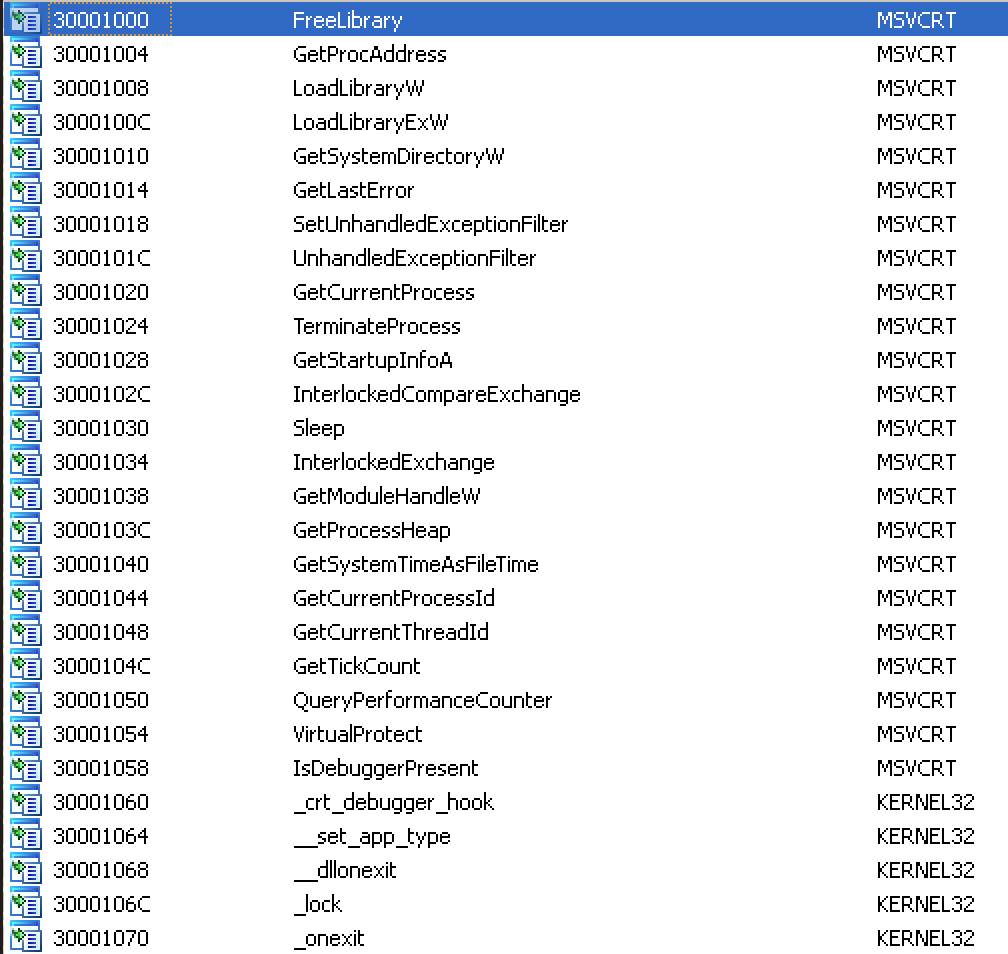
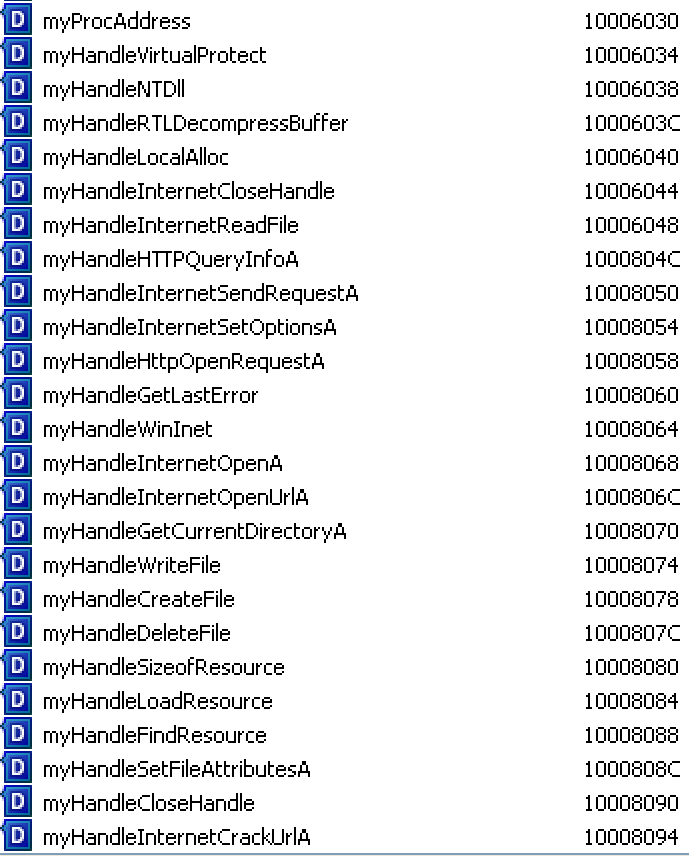
After decoding all the references, you can now see the true list of imports – all the handle variables created to hold handles to DLLs and functions with hidden names:
There’s lot of interesting internet-related calls, along with memory allocation, resource handling, and we see VirtualProtect() again.
File 4-1 – *.exe Static Analysis:
I did the same function analysis and renaming as I did to the DLL. There weren’t as many functions (some were just one-line functions that called other functions and weren’t worth renaming) and the executable didn’t use the same string-hiding technique so my guess is that it was compiled separately.
You can see some calls that register the DLL with the operating system, and CheckDebuggerPresent() again.
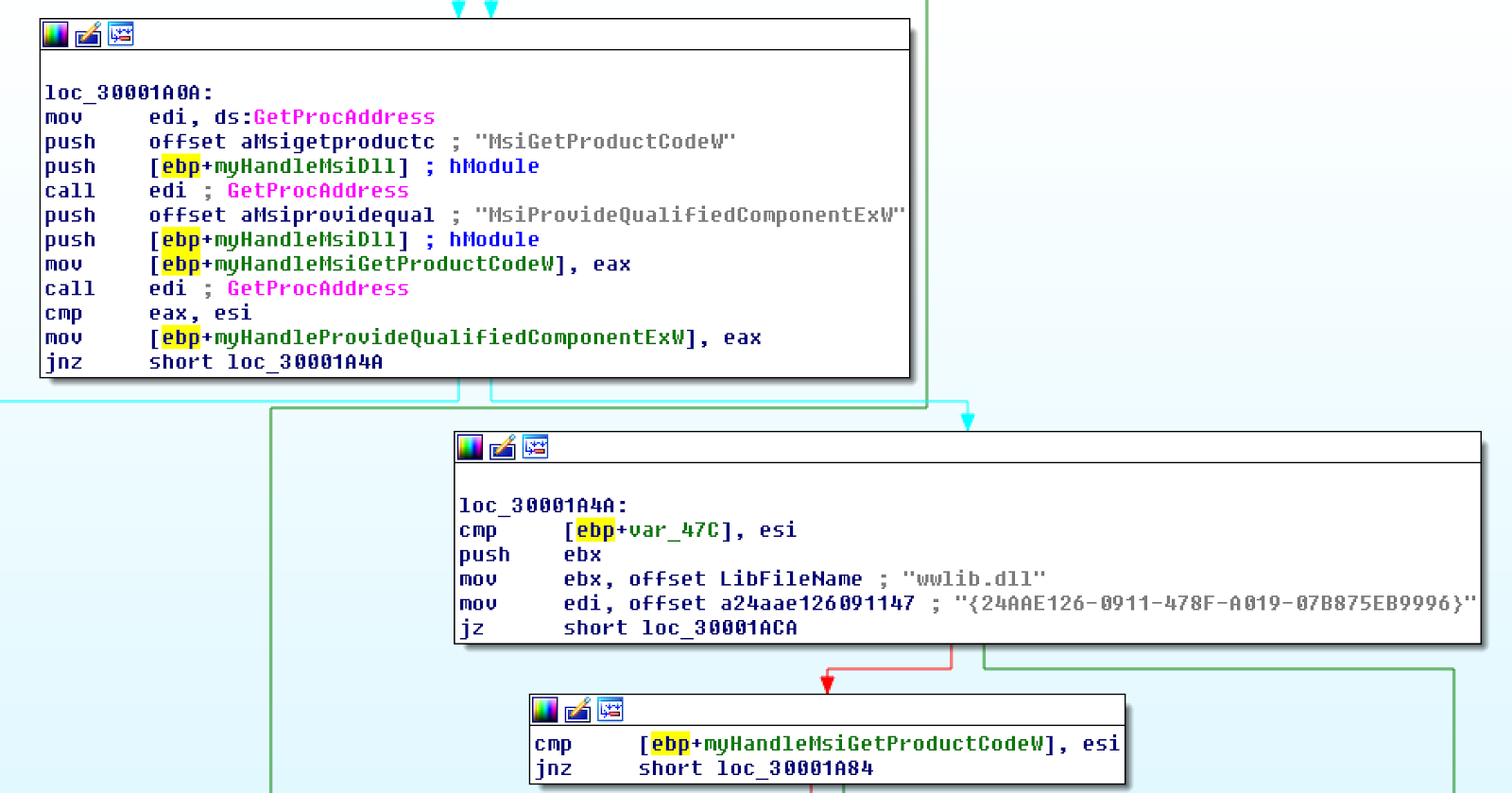
This function appears to be the code that actually registers wwlib.dll with the OS. The hexadecimal string is a provided Component ID:
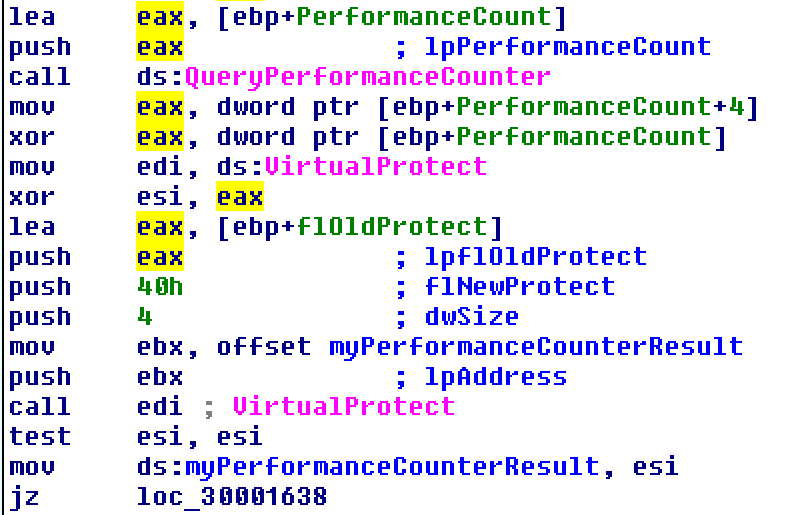
The malware appears to use a performance counter check to see if it is running on a virtual machine, but there are still some things I don’t understand here.
… I don’t understand why it’s xor-ing the ESP register value with the stored performance counter result and then checking it against the original value.
At any rate the malware is expecting a particular value, and if it doesn’t see that value it calls a function which ends in terminating the process before it does anything.
The IsDebuggerPresent() check seems to be intended to actually help with debugging while developing the malware, rather than hindering reverse-engineering of it. It seems to raise an exception with the debugger to halt execution just before terminating the process.
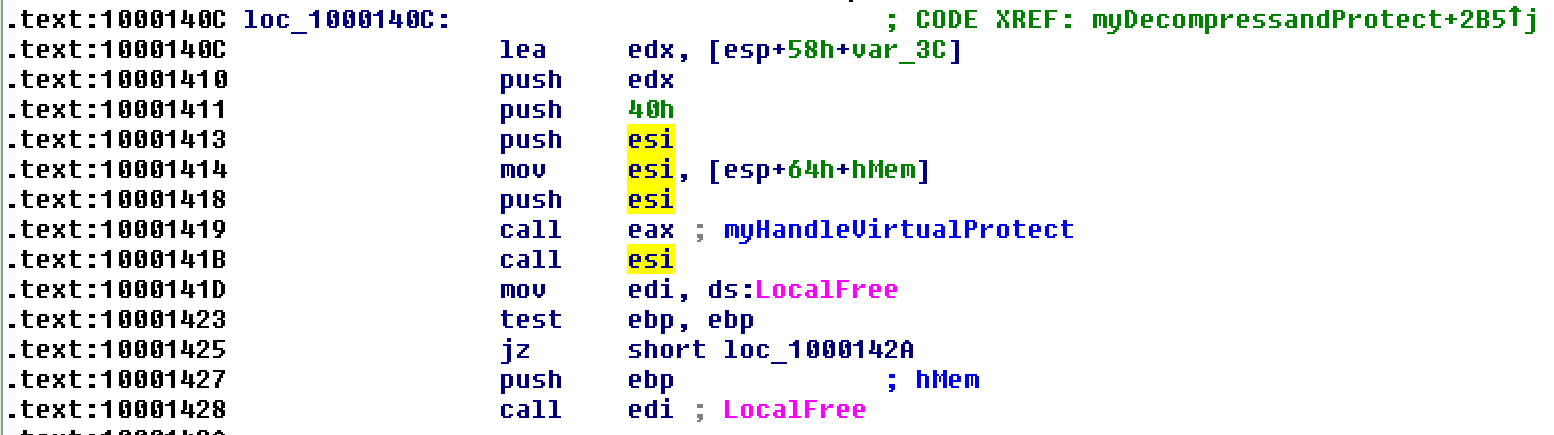
This next code block appears to be the core functionality – really the entire point of the malware. This is where the malware execution is transferred to the code that was downloaded from the website. Malware has copied the result of it’s unpacking/decoding routines into memory, called VirtualProtect() on that memory space to make it executable, and then (at 0x1000141B) makes a “call esi”, which tranfers execution to the address of the (now executable) memory block.
0x40 = PAGE_EXECUTE_READWRITE
File 4-1 – *.exe Dynamic Analysis – Executing the executable:
I set up Process Explorer and Process Monitor, Wireshark, ApateDNS and regshot.
When you double-click on the file, the malware executable runs and immediately creates a file with the same root name that looks like a Word doc –
and then it exits after a few seconds. I couldn’t see any sign that the DLL or a new process is still running – perhaps I failed the performance check.
I had to install 32-bit Word reader and some compatibility updates, but was able to open the .doc file in my secure environment:
I have no idea about the accuracy of the contents of this file, but it doesn’t really matter. The important thing to me is the date – the date indicates the malware was created in the last 3-4 months. The .doc didn’t ask me to enable macros or anything. Later I realized that if I had had the Word reader installed already it would have opened the file before exiting – so I think the Word .doc exists solely to give the impression that you did, in fact, open a Word document as intended instead of what you actually did – run a malicious executable.
File 4-1 – *.exe Dynamic Analysis – Debugging with Ollydbg:
I set breakpoints around the CheckforDebugger() calls:
The call for the routine that I think installs wwlib.dll:
The call to the DLL’s FMain() function:
And a function that does some sort of transform on the downloaded data:
Execution stopped at the breakpoint just before the ShellExecute() call:
This is the code that opens the Word .doc that it created in order to make it look like we actually clicked on a Word doc file instead of a malicious executable.
Tracing through the program enabled me to reach some of the conclusion I’ve detailed above.
Conclusions:
In the original archive we appear to have a 32-bit version of the loader, I’m guessing a 64-bit version of the loader (File #5), three different versions of “wwlib.dll” (Files #2, #3, and #4-1), and another DLL I haven’t looked at yet (File #1). Given the two different documents we saw reference to (one related to Hong Kong, one related to Islam), the files appear to be a ruse to get people of different nationalities/religions to run the executable, and hide the fact that they did anything other than opening a Word document.
The executable appears to simply exist as a loader to install and execute the DLL, and the DLL appears to simply download code from a website and execute it. If the website is unreachable the malware doesn’t appear to be able to do anything to maintain presence or re-try the connection.
Analysis still to do:
I didn’t see that the DLL was executing in a resident process on my machine after execution. Further debugging is necessary to study and see if bypassing the performance monitor checks allows persistence. It’s possible there isn’t really any persistence yet though, that that would be handled by code that is downloaded and executed.
There is a dense block of assembly in the DLL that calls an external function to decompress and then does an internal transform (unpacking or decoding) on the data received over HTTP. The URL is not active anymore, so opening the HTTP session fails. I’d like to set up a server with a fake hk.dat file and trace what the DLL does with the data.
Likewise, I can’t exercise the code that transfers execution to the downloaded code block without a block of code to try. I would love to find a wild copy of hk.dat.
I plan to spin up a secure 64-bit environment to examine the 64-bit executable/loader.
I will also examine DLL File #1.
Other Analysts:
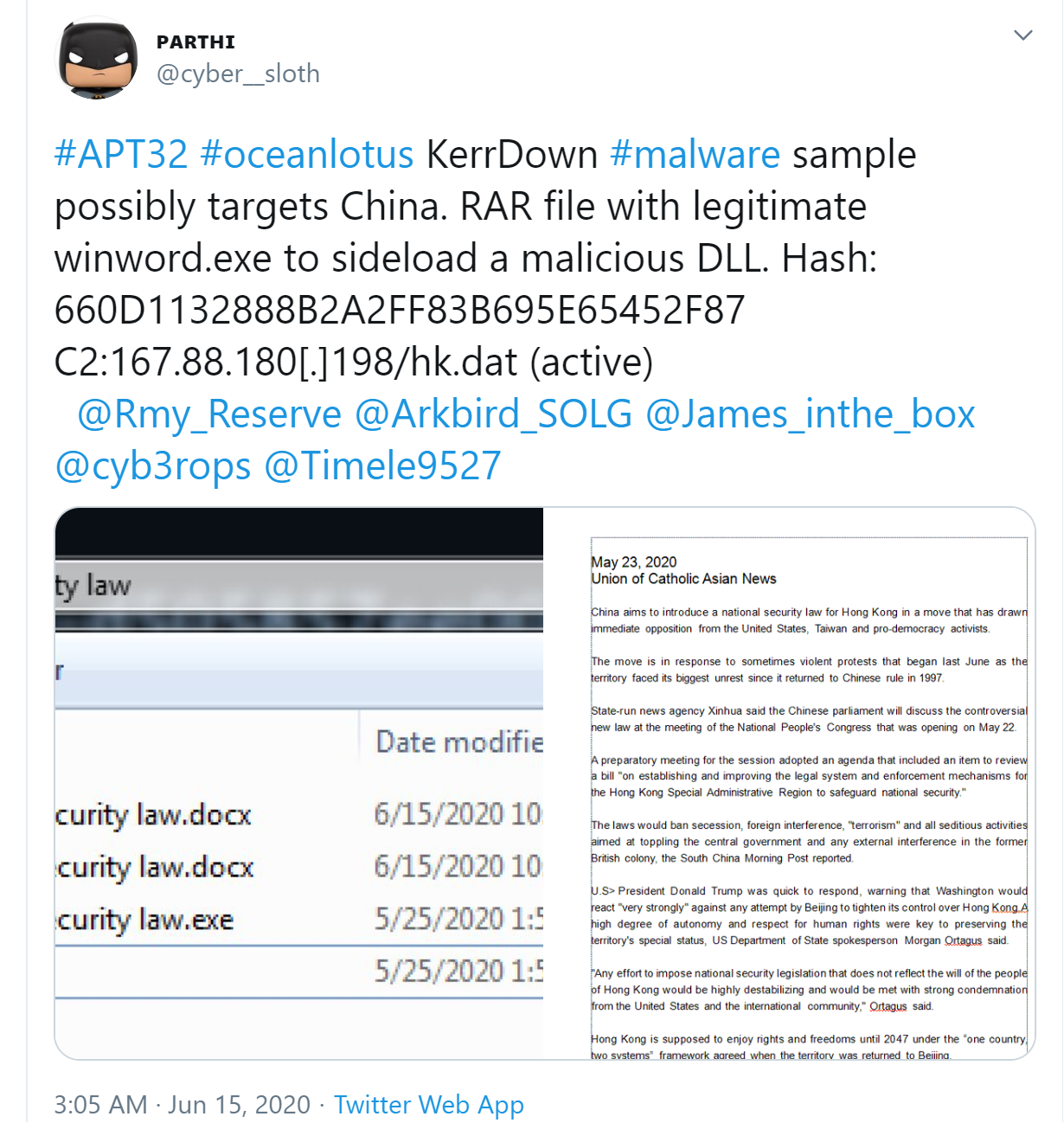
After determining the full URL the malware was trying to access, I was able to search for ‘hk.dat’ and found one reference to someone on Twitter doing their own analysis of this malware:
Thank you for reading! It was really fun to find out that I had the skills to grab a sight-unseen recent malware – created just in the last few months – and be able to figure out what it was trying to accomplish and how it worked.
I will continue the analysis of the other files in Part 2!
I started this blog back in the spring in order to participate in the security community, share what I was learning, and document my projects and interests. Then I started a Masters program right as Covid hit – I was taking classes from home, the kids were suddenly doing all their school from home, the world was seemingly falling apart and I got involved in a Covid-related tech project, so posting went by the wayside.
I’ve also learned that when I get stressed out or depressed I tend to isolate myself, so I’m making more of an effort to reach out and connect and participate in community.
I feel lucky that I’ve had this time to focus on school and spend time with the kids. I’ve been learning a lot through my classes, am excited about turning my career more in the direction of cybersecurity and am going to pick up again, start summarizing some of what I’ve been learning and posting it here.
I hope you and yours are safe and well, please reach out if you want someone to talk to, either for emotional support or just tech talk.
I had started a list for myself of interesting-looking resources for self-training while I’m working on my masters program, but then everyone’s favorite virus started circulating and suddenly a lot of conferences are going virtual and people are exchanging on-line resources and communities. I’ve been intercepting as many as I can and collecting them into this spreadsheet.
There are a couple of pop-up free conferences (PancakesCon this weekend, and AllTheTalks.online), but most already-planned conferences have either cancelled or gone virtual as well. Those are still generally charging convention-level registration though, so costs my be prohibitive for non-corporate-sponsored attendees although some *do* have student rates.
Azeria @Fox0x01 was awesome enough to post her Survival Guide for Social Distancing – a comprehensive list of links to resources for everything from Pentesting IoT devices to “Learning how to Learn”. I intend to work my way through this exceptionally thorough list, and I expect it will take a long, long time. I’ve found other sites with lists of resources and conferences, and some infosec/hacking/exploit/bug bounty communities it may be worthwhile to join.
I will keep adding to the spreadsheet as I find new resources and listings. If you have any favorite resources, tutorials, CTFs or communities, let me know in the comments and I’ll add them!
Update: This event was cancelled. I will try to catch the updates and follow up here.
If you buy a ticket and show up at Portland State University on March 25th, author and Chief Security Officer Marcus H. Sachs will be presenting a brief history of cryptography and a live demonstration of an original WWII Enigma encryption machine along with a networking event.
I’m not sure if I can make it that night, but I drool over old cryptography and telephony hardware and love the stories and history that go along with each surviving device.
I first heard about “fuzzing” about 15 years ago when it started circulating around the security community, and basically blew it off at the time. I said to myself something like “Eh, that’s just throwing random data at a program to see if it crashes. That may be useful, but isn’t really interesting.”, and proceeded to not pay much attention to it.
As a hardware validator that’s what I did – I generated tests with constrained random outputs to drive the hardware inputs and then watched to see if it did something unexpected. Fuzzing seemed pretty basic, and I figured it was one of those security fads that was hyped up with a cool-sounding buzzword that would vanish back into the ether. Some friends even created a fuzzing tool, and I was too blase` (and to be fair, distracted with a full-time job and kids) to pay a lot of attention to it at the time.
In my recent research efforts I attended a number of fuzzing-related presentations and started actually paying attention, and am now here to eat crow. My initial assessment wasn’t wrong exactly, “fuzzing” really is just a slang term for constrained-random testing – throwing random data at a program to see if it crashes. I pretty much entirely missed the point though, and the fact that all the stuff around that process is super interesting.
On the input side there are all sorts of algorithms for either generating new random data or taking example data and morphing it in random ways. On the output side you not only detect that your target program has crashed, but there are all sort of cool ways to get more information on how it crashed. You can then feed that output knowledge back into your input algorithm to get more targeted test data and find more crashes faster. Researchers are currently busy figuring out how to tie in machine learning algorithms to improve pattern matching. The problem space is so insanely huge that the art is in trimming it down – figuring out how to craft targeted input data to minimize your effort.
Then there’s all the cool stuff around creating harnesses to run your target software in the first place. You may be fuzzing a software library, so you may have to create a program around it to feed in data. Or you may be fuzzing firmware for an embedded system, so you have to either instrument a physical platform or emulate the whole thing in software. If you go the emulation route you may want to speed things up by replacing hardware function calls with faster software which is good, but creates a less realistic model. There’s an art to getting software from whatever program or device and instrumenting it so you can run fuzzing tools.
There’s the code coverage tools – disassembling your program and watching how it runs to see if you’ve exercised all the code. Particularly because you may not have access to the original source code. If you only execute half of the program you’re potentially missing a lot of bugs, so analyzing inputs that cause crashes on one code path can help find inputs that exercise other code paths. There’s an art to figuring out how to exercise the whole program.
Once your target program crashes, indicating a potential hole, how do you determine if that is a real vulnerability and not a problem with your software? If it is a real vulnerability how do you craft an exploit that you can use? There’s an art to going from crash to exploit.
What if you’re not fuzzing a program, but a web page or service or endpoint remotely? There’s a whole ‘nother set of arts and tools around that.
Each one of these things is an entire discipline in and of itself, and researchers are busy creating new and cool tools to do all of them in faster and better ways. I’m just scratching the surface here, but it is obvious that fuzzing works, and will continue to improve – getting more and more use and better and better tools. Companies are setting up ci/cd flows where they run fuzzers against their software continually in huge server farms, trying to catch bugs in each new version before release. Researchers are busy working their way through all the open-source software that exists and finding vulnerabilities that have been undetected for years. The security race never stops, and fuzzing is driving a huge part of it now.
I’m definitely arriving late to the party – it’s simply amazing what everyone has been busy doing in this space. Coming from a hardware validation perspective though the core random-constrained testing methodology is the same, so it’s like someone took my car, mounted a jet engine on the back, and pushed the button. It’s cool looking ahead and trying to figure out where the rocket is going while I run my fastest to catch up.
As I continue to learn this I’ll do my best to create digestible summaries and tutorials, so stay tuned!
In the way of introductions – Hi, my name is Charley. I’m using this site as a vehicle for exploring current trends in the world of hardware security and sharing what I learn along the way.
I’ve been in the tech industry for 20 years, plus a couple of summer internships. Most of my career has been in the world of digital hardware design and validation – developing Verilog RTL, writing testbenches and tests, debugging, code coverage, FPGAs. Security has long been an interest of mine though – I completed a computer forensics certification at Lake Washington Tech and was a hardware security architect at Intel for two years. To drive my career further in that vein I’ve decided to pursue a Masters in Cybersecurity at Portland State.
I learn better when I’m trying to explain things to other people in turn, so that’s why I’m here. I will be doing security research – following personal projects or what I need for school – and then turning around and posting summaries, tutorials and documentation here. Please engage to offer recommendations, tools, or corrections, we’re all in this together.
My goal is to spin this up into my own security consulting company as well, doing security research and analysis of embedded/IoT devices. We have a learning curve ahead of us though, so let’s get started!